When designing a synthesizer or a sampler, how should you interpret MIDI pitchbend messages so that they’ll have the desired effect on your sound? First let’s review a few truisms about MIDI pitchbend messages.
1. A pitchbend message consists of three bytes: the status byte (which says “I’m a pitchbend message,” and which also tells what MIDI channel the message is on), the least significant data byte (you can think of this as the fine resolution information, because it contains the 7 least significant bits of the bend value), and the most significant data byte (you can think of this as the coarse resolution information, because it contains the 7 most significant bits of the bend value).
2. Some devices ignore the least significant byte (LSB), simply setting it to 0, and use only the most significant byte (MSB). To do so means having only 128 gradations of bend information (values 0-127 in the MSB). In your synthesizer there’s really no reason to ignore the LSB. If it’s always 0, you’ll still have 128 equally spaced values, based on the MSB alone.
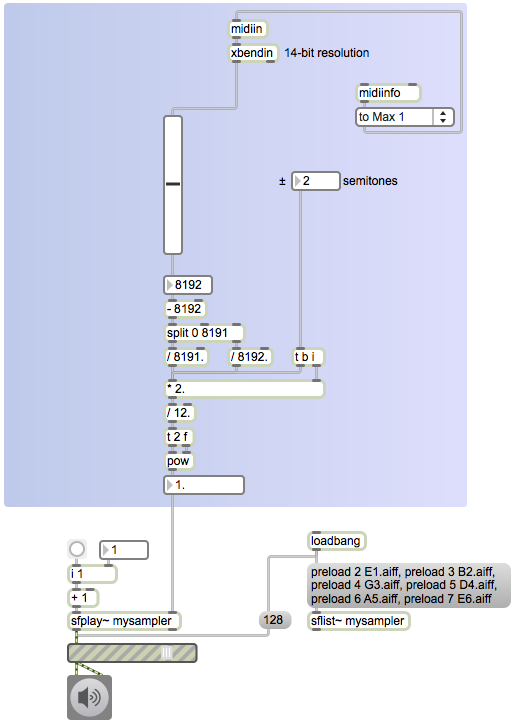
3. Remember that all MIDI data bytes have their first (most significant) bit clear (0), so it’s really only the other 7 bits that contain useful information. Thus each data byte has a useful range from 0 to 127. In the pitchbend message, we combine the two bytes (the LSB and the MSB) to make a single 14-bit value that has a range from 0 to 16,383. We do that by bit-shifting the MSB 7 bits to the left and combining that with the LSB using a bitwise OR operation (or by addition). So, for example, if we receive a MIDI message “224 120 95” that means “pitchbend on channel 1 with a coarse setting of 95 and a fine resolution of 120 (i.e., 120/128 of the way from 95 to 96)”. If we bit-shift 95 (binary 1011111) to the left by 7 bits we get 12,160 (binary 10111110000000), and if we then combine that with the LSB value 120 (binary 1111000) by a bitwise OR or by addition, we get 12,280 (binary 10111111111000).
4. The MIDI protocol specifies that a pitchbend value of 8192 (MSB of 64 and LSB of 0) means no bend. Thus, on the scale from 0 to 16,383, a value of 0 means maximum downward bend, 8,192 means no bend, and 16,383 means maximum upward bend. Almost all pitchbend wheels on MIDI controllers use a spring mechanism that has the dual function of a) providing tactile resistance feedback as one moves the wheel away from its centered position and b) snapping the wheel quickly back to its centered position when it’s not being manipulated.
5. The amount of alteration in pitch caused by the pitchbend value is determined by the receiving device (i.e., the synthesizer or sampler). A standard setting is variation by + or – 2 semitones. (For example, the note C could be bent as low as Bb or as high as D.) Most synthesizers provide some way (often buried rather deep in some submenu of its user interface) to change the range of pitchbend to be + or – some other number of semitones.
So, to manage the pitchbend data and use it to alter the pitch of a tone in a synthesizer we need to do the following steps.
1. Combine the MSB and LSB to get a 14-bit value.
2. Map that value (which will be in the range 0 to 16,383) to reside in the range -1 to 1.
3. Multiply that by the number of semitones in the ± bend range.
4. Divide that by 12 (the number of equal-tempered semitones in an octave) and use the result as the exponent of 2 to get the pitchbend factor (the value by which we will multiply the base frequency of the tone or the playback rate of the sample).
A pitchbend value of 8,192 (MSB 64 and LSB 0) will mean 0 bend, producing a pitchbend factor of 2(0/12) which is 1; multiplying by that factor will cause no change in frequency. Using the example message from above, a pitchbend of 12,280 will be an upward bend of 4,088/8191=0.499. That is, 12,280 is 4,088 greater than 8,192, so it’s about 0.499 of the way from no bend (8,192) to maximum upward bend (16,383). Thus, if we assume a pitchbend range setting of ± 2 semitones, the amount of pitch bend would be about 0.998 semitones, so the frequency scaling factor will be 2(0.998/12), which is about 1.059. You would multiply that factor by the fundamental frequency of the tone being produced by your synthesizer to get the instantaneous frequency of the note. Or, if you’re making a sampling synthesizer, you would use that factor to alter the desired playback rate of the sample.
See a demonstration of this process in the provided example “Using MIDI pitchbend data in MSP“. The process is also demonstrated in MSP Tutorial 18: “Mapping MIDI to MSP“.