
The MP3 Learning Object by Nathaniel Tull Phillips is a tutorial that describes the MP3 audio compression method.
How Much Do Music Artists Earn Online?
Link
I can’t vouch for the veracity of this graph, but if it’s even close to accurate it’s instructive. It estimates how much distribution of a musician’s work would be required each month to earn U.S. minimum wage, and visualizes the data as comparably-sized circular areas. Clearly recorded music is not a primary source of income for very many people.
How Much Do Music Artists Earn Online?
by David McCandless
How to mix more than four tracks in MuLab Free
To mix more than four tracks together in MuLab, you’ll need to use the same trick the Beatles did when making the Sergeant Pepper’s Lonely Heart’s Club Band album with 4-track tape recorders.
Once you get up to four tracks (but not more than four), and you have something that you like (with all the panning, volume control, etc.), save that session, then choose Mixdown Audio from the Session menu to mix what you’ve done so far down to a single stereo file. Then close that session (quit MuLab entirely and then reopen it), open a new empty session, and drag your mixed-down audio file into your new session. That will be one track, but you’ll now be able to add up to three more tracks to it. (And if you decide you want to change something about the mixed-down audio, you can always go back to your first session, make whatever changes you need to make, then repeat the Mixdown Audio process to get a revised version.)
You can repeat that process as many times as you need to, in order to mix together as many sounds as you want. There’s no loss in sound quality because it’s rendering everything exactly as you specified it in your original session.
Track 1 — \
Track 2 — \ ___mixed down to … Track 1 — \
Track 3 — / and add … Track 2 — \___mixed down to … Track 1 —
Track 4 — / Track 3 — / and add … more tracks, etc.
. Track 4 — /
Timeline
Here is a timeline of some of the significant technological innovations and musical compositions discussed in class.
1787 — The composition of Musikalisches Würfenspiel, attributed to Wolfgang Amadeus Mozart, and considered to be one of the earliest examples of algorithmic composition; the roll of dice was used to choose a measure of music from among a collection of possibilities, and after several such dice rolls a full composition would have been completed by assembling suitable measures. There were literally quadrillions of possible compositions that theoretically could be generated by this system.
…
1877 — Invention of the phonograph by Thomas Alva Edison, a device that recorded sound by inscribing an indentation into a tinfoil sheet on a cylinder such that the variations in the indentation were analogous to the amplitude of the sound; the sound of the stylus being dragged lightly on that surface at a later time could be amplified to audible level, allowing the previously inscribed sound to be heard back.
1886 — Invention of the graphophone by Alexander Graham Bell, which differed from the phonograph in that it inscribed the sound horizontally on wax-covered cardboard cylinders, making the recordings better-sounding and more durable.
1887 — Emile Berliner patented the gramophone, which etched the sound horizontally in a spiral on a wax-coated disc. The disc would prove to be the preferred recording format.
1896 — Invention of the telharmonium, generally considered the first electronic instrument, by Thaddeus Cahill, whose idea was for the sound of the telharmonium to be transmitted via telephone lines to homes and places of business, which would license the music service for a fee.
1899 — Maple Leaf Rag by Scott Joplin, which was recorded by the composer on a player piano scroll in the early 20th century; the player piano was a significant music storage/retrieval invention of the turn of the 20th century that enjoyed popularity in the first quarter of that century.
1920 — Invention of the theremin (a.k.a. thereminvox) by Leon Theremin, an electronic musical instrument that could be performed (could be controlled in its pitch and its volume) without the performer physically touching the instrument.
1924 — Ballet Mécanique by George Antheil was a large composition for pianos, player pianos, percussion instruments, sirens, and airplane propellers; it was intended to accompany a film of the same name by Fernand Léger.
1928 — The theremin was patented in the U.S. It would later be the first product manufactured by synthesizer pioneer Robert Moog, and would still later be used as a special melodic effect in compositions such as Good Vibrations by the Beach Boys and the theme for the TV show Star Trek.
1932 — The first commercially available electric guitar was produced by Adolph Rickenbacker and George Beauchamp. Guitars were amplified to compete in loudness with other band instruments. The fact that the vibration of the guitar’s strings was transduced into an electrical signal meant that its sound could be easily altered and distorted to get an extremely wide range of timbres, which were exploited by rock musicians.
1935 — The Gibson guitar company announces its production of the ES-150 “Electric Spanish” archtop electric guitar. Gibson remains one of the foremost manufacturers of electric guitars, the makers of several famous models popular among rock guitarists, including the Les Paul, the ES-335, the SG, and the Flying V.
1935 — The Magnetophon tape recorder was developed by AEG Telefunken in Germany, featuring lightweight tape (instead of the heavy, dangerous metal tape used in some prior devices) and a ring-shaped magnetic head. Although not commercially available for about another decade, this was the fundamental design of later models.
1948 — The Ampex company in America, with financial backing from radio star Bing Crosby, produced a commercially available tape recorder, the Model 200. The availability of tape recording made it much easier to record large amounts of sound material for radio broadcasts and records.
1948 — Etude aux chemins de fer by Pierre Schaeffer was one of the first examples of musique concrète, music composed entirely of recorded non-instrumental sounds. He recorded railroad sounds on discs, and developed techniques of looping, editing, and mixing to compose music with those sounds.
1950 — Alan Turing describes a definition of artificial intelligence in his article “Computing Machinery and Intelligence“.
1956 — Louis and Bebe Barron produced a soundtrack score for the film Forbidden Planet that consisted entirely of electronic sounds they generated with their own homemade circuitry. The musicians’ union convinced MGM not to bill their work as music, so they were credited with “electronic tonalities”.
1956 — German composer Karheinz Stockhausen composed Gesang der Jünglinge for electronic and concrete sounds.
1956 — Lejaren Hiller and Leonard Isaacson programmed the Illiac I computer at the University of Illinois to compose the Illiac Suite for string quartet, the earliest example of algorithmic music composition carried out by a computer.
1958 — Edgard Varèse composed Poème électronique for electronic and concrete sounds, which was composed to be played out of multiple speakers inside the Philips Pavilion at the 1958 World’s Fair in Brussels, an innovative building design credited to Le Corbusier but largely designed by architect/engineer/composer Iannis Xenakis.
1958 — Luciano Berio composed Thema (Omaggio a Joyce), a tape composition in which the initial “theme” is a reading by Cathy Berberian of text written by James Joyce, and the recording is used as the source material for the remainder of the composition, made by editing and mixing Berberian’s taped voice.
1950s — Early experimentation in the musical application of computers included attempts at algorithmic composition by Hiller and Isaacson (resulting in the Illiac Suite in 1956) and work on audio and voice synthesis at Bell Labs, resulting in Max Mathews‘s MUSIC programming language, the precursor to many subsequent similar music programming languages (known collectively as Music N languages).
1950s — American expatriate composer Conlon Nancarrow composed the majority of his Studies for Player Piano during this decade, including Study No. 21, also known as Canon X, a composition in which two melodic lines constantly change tempo in opposite ways. Nancarrow punched the notes of his compositions into player piano scrolls by hand. The mechanical means of performing the music permitted him to explore musical ideas involving very complex rhythm and tempo relationships that are practically impossible for human performers.
1961 — Max Mathews and others at Bell Labs synthesize a singing voice and a piano in a completely digitally-produced rendition of the song Daisy Bell (A Bicycle Built for Two).
1964 — Understanding Media, a critique of media and technology by Marshall McLuhan.
1968 — Revolution 9, a musique concrète composition by The Beatles (credited to Lennon-McCartney, but composed primarily by John Lennon with the assistance of Yoko Ono and George Harrison), demonstrating the artists’ interest in avant garde contemporary art and music. It was remarkable for a popular rock group of their stature to include such music on an album rock music.
1968 — Switched-On Bach was an album of compositions by Baroque-period German composer Johann Sebastian Bach performed (with overdubbing) on a Moog modular synthesizer by Wendy Carlos. The album popularized the sound of electronic music and even made it to the Billboard Top 40 and won three Grammy awards.
1968 — Composer Steve Reich noticed that when a suspended microphone swung past a loudspeaker it momentarily produced a feedback tone. This inspired him to make Pendulum Music, a piece in which several suspended microphones are swung pendulum-like over loudspeakers to produce feedback tones periodically. The tones happened at different periodicities based on the rate at which each microphone swung, creating an unpredictable rhythmic counterpoint. This type of piece was consistent with the conceptual art of the 1960s, in which the idea behind the creation of the artwork was considered more important than, or even considered to be, the artwork itself. It’s also an example of process music, in which a process is enacted and allowed to play out, and the result of that process is the composition. It led to other process pieces by Reich (and soon by others, too) such as his tape loop pieces It’s Gonna Rain and Come Out, and instrumental process pieces such as Piano Phase.
1960s — Robert Moog developed the voltage-controlled modular synthesizer, made famous by Wendy Carlos’s album Switched-On Bach, and used by various experimental composers and popular musicians. The synthesizer consisted of a cabinet filled with diverse sound-generating and sound-processing modules that could be interconnected with patch cords in any way the user desired. A significant feature was the ability to use oscillators not only as sound signals but also as control signals to modulate the frequency of other oscillators, the gain of amplifiers, and the cutoff frequency of filters.
1972 — The end of the tune From the Beginning by Emerson, Lake & Palmer includes a Moog modular synthesizer solo. The Moog modular was included in studio recordings of several rock bands of that period. However, the later Minimoog synthesizer proved more popular for live performances for various reasons, especially its relative simplicity and compactness.
1976 — The Minimoog synthesizer included a pitchbend wheel and a modulation wheel next to the keyboard for additional expressive control. Few people mastered the Minimoog (and the pitchbend wheel) more than Chick Corea, who used the Minimoog in the jazz-rock group Return to Forever. The tune Duel of the Jester and the Tyrant includes a good example of Corea’s prowess on the Minimoog.
1977 — Producer-composer Giorgio Moroder was the producer of the disco hit I Feel Love by Donna Summer, in which the instrumental accompaniment is completely electronic.
1978 — Giorgio Moroder is well known for composing the film score Midnight Express, the Chase theme of which typifies the driving rhythmic periodic electronic sequences in the score. Moroder used a wide range of synthesizers (Moog, Minimoog, ARP, etc.) and other electronic keyboards.
1978 —The German band Kraftwerk composed synthesizer music that seemed to comment on the mechanization and dehumanization of modern technological society. Their song The Robots, composed with synthesizers such as the Minimoog, overtly sings of cyberbeings, but may in fact be a commentary on class disparities, evoking a dehumanized working class.
1980 — John Searle published “Minds, Brains, Programs“, an article disputing Alan Turing’s definition of intelligence.
early 1980s — The MIDI protocol for communication between digital instruments was established by music manufacturers.
1980s — David Cope began to develop his Experiments in Musical Intelligence (EMI) software, which composed music convincingly in the style of famous composers.
1985 — Degueudoudeloupe is an algorithmic composition by Christopher Dobrian composed and synthesized by computer (programmed by the composer) exploring computer decision making in metric modulations, and using continually changing tuning systems.
1989 — The Vanity of Words by Roger Reynolds uses computer algorithms to edit and process the voice of baritone Philip Larson reciting text by Milan Kundera, resulting in a digital form of musique concrète, in concept not unlike the 1958 composition Thema (Omaggio a Joyce) by Luciano Berio.
1991 — Entropy, an algorithmic composition for computer-controlled piano and computer graphics by Christopher Dobrian, exploring the use of changing statistical probabilities as a way of organizing a musical composition.
1994 — Textorias for computer-edited guitar by Arthur Kampelas demonstrates how intricate digital editing can be used to organize a highly gestural modern-day musique concrète composition.
1995 — Barrage No. 4, a composition for computer-edited electric guitar sounds by John Stevens, a digital form of musique concrète; the guitar sounds are very noisy and of radically changing pitch, defying classification as traditional instrumental sound.
1997 — Rag (After Joplin) is a piano rag composed by David Cope‘s artificially intelligent EMI software emulating the musical style of famous ragtime composer Scott Joplin. Cope’s software draws on databases of compositions by famous composers, and reorders moments of those compositions, resulting in new works that are remarkably similar stylistically to the composer’s actual works.
1998 — There’s Just One Thing You Need To Know is a computer music composition by Christopher Dobrian for computerized piano (Yamaha Disklavier), synthesizer, and interactive computer system in which the computer responds to the performed piano music with synthesizer accompaniment and even algorithmic improvisations of its own.
2000 — Microepiphanies: A Digital Opera is a full-length theatrical music and multimedia performance by Christopher Dobrian and Douglas-Scott Goheen in which the music, sound, lights, and projections are all controlled by computer in response to the actions of the live performers onstage, without there being any offstage technicians running the show.
2003 — Mannam is a composition by Christopher Dobrian for daegeum (Korean traditional bamboo flute) and interactive computer system, featuring interactive processing of the flute’s sound as well as synthesized and algorithmically-arranged accompaniments.
2005 — Data.Microhelix by Ryoji Ikeda, exclusively used digital “glitches” as the fundamental musical material, an example of the so-called “aesthetics of failure”.
2011 — Eigenspace by Mari Kimura employed the “augmented violin” gesture-following system developed at IRCAM to control the type of audio processing that would be applied to her violin sound in real time.
2013 — Modus 01 by Danny Sanchez used sounds triggered by piano to make an interactive combination of piano and glitch.
Recent computer music technologies and aesthetics
Link
The “New Aesthetic“
Ferruccio Laviani (Fratelli Boffi)
– Good Vibrations furniture designs
Pixelated scupture
– The pixelated animals of Shawn Smith
– Digital Orca by Douglas Coupland
“Glitch“
“The Aesthetics of Failure” (or just more “new aesthetic”?)
Ryoji Ikeda
– Data.Microhelix
– .mzik
– The Transfinite
Danny Sanchez
– Modus 01
Gesture following
IRCAM IMTR
– Gesture Follower
Mari Kimura (IRCAM)
– Augmented violin
– Eigenspace
Sergi Jordà (MTG)
– Reactable
Christopher Dobrian
– MCM
– Gestural
Kinect, Wii, etc.
Robotic musicmaking
LEMUR
– JazzBot
Byeong Sam Jeon
– Telematic Drum Circle
Laptop orchestras
PLOrk
– performance video
SLOrk
– television news feature
Telematic Performance
JackTrip
Dessen, Dresser, et al
Byeong Sam Jeon
Live Coding
ChucK
Reactable
Some significant dates mentioned in the history of music technology
Here is a list of dates that were noted as being in some way significant in the recent history of music technology. A good way to get a sense of the historical timeline of events, not to mention to study for the final exam, is to identify what events or pieces of music correspond to the dates given here. The process of doing that will help to register in your mind the approximate time of events and their sequence relative to one another. Make a copy of this list of dates, and place events or titles of works on the list next to the appropriate dates. Start by working from memory, and then consult your class notes and the posts of this website to refresh your memory.
1787
…
1877
1887
1896
1899
1920
1924
1928
1948
1950
1956
1956
1956
1958
1958
1950s
1950s
1964
1968
1968
1960s
1972
1976
1977
1978
1978
1980
early 1980s
1980s
1985
1989
1991
1994
1995
1997
1998
2000
2003
Dobrian’s early interactive compositions
As computer processing speed became faster, in the 1980s and 1990s it became clear that a computer program could compose and synthesize sound instantaneously “in real time”, meaning “without noticeable time delay”. Composing in real time is essentially what people often mean when they use the word “improvisation”; a person (or computer) makes up music and performs it at the same time. However, improvisation between two or more musicians involves the important components of listening to the music others are making, reacting in real time to what others do, and interacting with them. Can computer improvisation incorporate these apparently very human traits of listening, reacting, and interacting?
Artificial intelligence is defined by some as having the quality or appearance of intelligent behavior, of successfully imitating human intelligence even if lacking the awareness and understanding that humans have. Similarly, computer perception, cognition, and reaction/interaction can be successfully emulated to the point where we might say the computer exhibits the qualities of those abilities, even if we know it is not actually “hearing” or “interacting” the same way humans do. For this sort of emulation of interaction, we might say that the computer exhibits “interactivity”, the quality of interacting, even if its way of doing so is different from that of a human.
In the 1990s I began to focus less on music in which the computer composed and performed/synthesized its own composition, and more on music that involved some sort of interactivity between the computer and a human performer in real time. In order for the computer to seem to be interactive, its program has to include some rudimentary form of perception and cognition of the musical events produced by the human, and it must also have some degree of autonomy and unpredictability. (If these factors are absent, the computer would be acting in a wholly deterministic way, and could not be said to be in any way truly interactive.)
In the composition There’s Just One Thing You Need To Know (1998) for Disklavier, synthesizer, and interactive computer system, the notes played by a human pianist are transmitted via MIDI to a computer program that responds and contributes musically in various ways.
The piece is composed as a “mini-concerto” for the Disklavier piano, which is accompanied by a Korg Wavestation A/D synthesizer controlled by Max software interacting automatically with the performer in real time. The conceptual and musical theme of the piece is “reflection”. The music composed for the pianist requires — almost without exception — symmetrical hand movement; one hand mirrors precisely the position of the other hand, albeit often with some delay or other rhythmic modification. Even the music played by the computer is at any given moment symmetrical around a given pitch axis. The human and computer performers also act as “mirror images” or “alter egos”, playing inverted versions of the other’s musical material, playing interlocking piano passages in which they share a single musical gesture, and reinforcing ideas presented by the other.
The computer plays three different roles in the piece. In one role, it is a quasi-intelligent accompanist, providing instantaneous synthesizer response to the notes played by the pianist. In a second role, the computer acts as an extension of the pianist’s body—an extra pair of virtual hands—playing the piano at the same time as the pianist, making it possible for the piano to do more than a single pianist could achieve. In a third role, the computer is an improviser, answering the pianist’s notes with musical ideas of its own composed on the spot in response to its perceptions of the pianist’s music.
The title comes from a statement made by composer Morton Feldman. “There’s just one thing you need to know to write music for piano. You’ve got a left hand, and you’ve got a right hand. [gleefully] That’s ‘counterpoint’!”
Another work composed shortly thereafter is Microepiphanies: A Digital Opera (2000), an hour-long multimedia theatrical and musical performance in which the music, sound, lights, and projections are all controlled by computer in response to the actions of the live performers onstage, without there being any offstage technicians running the show.
The performance is conceived as a satire of the tropes and cliches that were commonly found in performances of so-called interactive music of the time. The performers describe their activities to the audience (sometimes deceitfully) as they perform music with various unusual technological devices. Because the technology occasionally seems to malfunction, or functions mysteriously, it’s difficult for the audience to know the true extent to which the computer system is actually interactive. Because it’s made clear that there are in fact no offstage technicians aiding the performance, the apparent musical and interactive sophistication of the computer seems at times magical.
A couple years later I had the opportunity to spend a year living in Seoul, Korea. I was interested to see in what ways interactive computer music could be used in the context of traditional Korean music, not simply to use the sounds of Korean music as a sort of musical exoticism, but rather as a way to find a true symbiosis between two apparently disparate musical worlds, the traditional music of an Asian nation and the modern technological music being practiced in the West.
This project required that I study traditional Korean classical music as seriously as I could, in order to be properly knowledgeable and respectful of that music as I composed the music and designed software for interaction with a live musician. Because I had previously done a series of interactive pieces involving the flute, I chose to work with the Korean bamboo flute known called the daegeum. I was helped by Serin Hong, who was at that time a student of traditional Korean music at Chugye University, specializing in daegeum performance; Serin would play the music I composed for the instrument, and would give me criticism on any passages that were not sufficiently idiomatic or playable.
I eventually wrote a complex interactive computer program and composed a thirteen-minute piece titled Mannam (“Encounter”) (2003) for daegeum and interactive computer system, which was premiered by Serin Hong in the 2003 Seoul International Computer Music Festival.
The computer was programmed to capture the expressive information (pitch and volume fluctuations) from the live daegeum performance; the program used pitch, loudness, and timbre data to shape the computer’s sound synthesis and realtime processing. The computer modifies the sound of the daegum in real time, stores and reconfigures excerpts of the played music, and provides harmonic accompaniment in “intelligent” response to the daegeum notes. The daegeum music is composed in idiomatic style, and leaves the performer considerable opportunity for rubato, ornamentation, and even occasional reordering of phrases, in order to respond to the computer’s performance, which is different every time the piece is played.
The techniques I developed for tracking the performer’s nuances are described in detail in “Strategies for Continuous Pitch and Amplitude Tracking in Realtime Interactive Improvisation Software“, an article I wrote for the 2004 Sound and Music Computing conference in Paris.
Dobrian’s early algorithmic compositions
When I started learning about computer music in 1984, I became interested in the challenge of trying to program the computer to compose music. My first piece of computer music was an experiment in algorithmic composition focusing on automated composition of metric modulations. Since a metric modulation is essentially a mathematical operation, it seemed reasonable that a computer could calculate and perform such tempo changes more readily than humans. So I set out to write a computer program that would compose and synthesize music that included metric modulations.
The problem that I immediately confronted, though, is how to establish a clear sense of tempo and beat for the listener that would be musically interesting. It’s one thing to use standard Western notation to compose metric modulations on paper, but when there’s no paper or notation involved, and no human performers to add inflection to the music, it’s another thing to figure out exactly how to make the beat evident to the listener so that the metric modulation would be clearly audible.
I was obliged to answer the question, usually taken for granted by musicians, “What are the factors that give us a sense of beat?” The most obvious one is that things happen periodically at a regular rate somewhere roughly in the range of walking/running speed, say from 48 to 144 beats per minute. But music consists of more than simply a single constant rhythm, it contains a wide variety of rhythms. So how do we derive the beat? We use other factors that exhibit regularity such as dynamic accent (loudness), timbral accent (choice of instrument, brightness), melodic contour (a repeating shape), harmonic rhythm (implied chord changes), and harmonically-related beat divisions (triplets, sixteenths, quintuplets, etc.), and we take all of those into consideration simultaneously to figure out rates of repetition that might be considered the beat. (There are also stylistic considerations; we may be familiar with a body of works that all belong to the same style or genre, so that we have established cultural cues about where the beat is considered to be in that type of music.)
So I wrote a program in C that composed phrases of music, and that made probabilistic decisions along the way about how to modulate to a new harmonically-related tempo using beat divisions of the same speed in each tempo. It used factors of melodic contour, dynamic accent, and timbral accent to provide a sense of periodicity. (It incidentally also used continuously changing pitch ranges and continuously changing tuning systems, so that the music has a unique inharmonic character.) The program produced a type of musical score for each phrase of music, a time-tagged list of notes that would be used in the Cmusic sound synthesis language to synthesize the notes on a VAX 11/780 (Unix) computer and store the results in a sound file. (The sampling rate was a mere 16 kHz, but that was barely adequate for the sounds being synthesized.)
The composition was titled Degueudoudeloupe (1985), a nonsense word I thought was evocative of the kinds of sounds and rhythms in the piece. The sounds in the piece are string-like, drum-like, and bell-like sounds synthesized using two methods: Karplus-Strong synthesis and Frequency Modulation synthesis.
In another composition several years later I again used probabilistic computer decision making to compose time-tagged lists of notes, this time intended to be transmitted as MIDI note data to a Yamaha Disklavier computer-controlled piano. The program was written in the C language, and the MIDI data that that program produced was saved as a MIDI file on a Macintosh Plus computer and transmitted to the Disklavier.
The piece is titled Entropy (1991), and was largely inspired by the following passage from The Open Work by Umberto Eco:
Consider the chaotic effect (resulting from a sudden imposition of uniformity) of a strong wind on the innumerable grains of sand that compose a beach: amid this confusion, the action of a human foot on the surface of the beach constitutes a complex interaction of events that leads to the statistically very improbable configuration of a footprint. The organization of events that has produced this configuration, this form, is only temporary: the footprint will soon be swept away by the wind. In other words, a deviation from the general entropy curve (consisting of a decrease in entropy and the establishment of improbable order) will generally tend to be reabsorbed into the universal curve of increasing entropy. And yet, for a moment, the elemental chaos of this system has made room for the appearance of an order…
The composition was conceived as a vehicle with which to explore ideas of information theory and stochasticism in an artistic way. It explores the perception of randomness and order (entropy and negentropy) in musical structure, and demonstrates the use of stochasticism not only as a model for the distribution of sounds in time, but also as a method of variation of a harmonic “order”.
The notes of this piece were all chosen by a computer algorithm written by the composer. The algorithm takes as its input a description of some beginning and ending characteristics of a musical phrase, and outputs the note information necessary to realize a continuous transformation from the beginning to the ending state. Such a transformation can take place over any period of time desired by the composer (in this piece anywhere from 3 to 90 seconds). The input description is stated in terms of relative probabilities of different musical occurrences, thus allowing the composer to describe music which ranges between totally predictable (negentropic) and totally unpredictable (entropic), and which can transform gradually or suddenly from one to the other.
Artificial intelligence and algorithmic composition
The development of computers, and devices that have computers embedded within them, has encouraged the exploration of machines that perform human actions. This exploration includes software that performs intellectual tasks, such as playing chess and composing music, and software-hardware systems that control machines robotically to perform physical tasks.
In the early years of modern computer development, mathematician and computer scientist Alan Turing developed ideas about computational algorithms and artificial intelligence. He hypothesized about the fundamental definition and nature of intelligence in his 1950 article “Computing Machinery and Intelligence“. In that article he proposed what eventually came to be known as the Turing test, which, if passed by a computer would qualify that machine as exhibiting intelligence. His premise can be paraphrased as implying that the appearance of human intelligence, if it is indistinguishable from real human behavior, is equivalent to real intelligence, because we recognize intelligence only by witnessing its manifestation. (This assertion was interestingly disputed by John Searle in his 1980 article “Minds, Brains, and Programs“.)
How can musical intelligence, as manifested in music composition, be emulated by a computer? To the extent that musical composition is a rational act, one can describe the methodology employed, and perhaps can even define it in terms of a logical series of steps, an algorithm.
An early example of a music composition algorithm is a composition usually attributed to Wolfgang Amadeus Mozart, the Musikalisches Würfelspiel (musical dice game), which describes a method for generating a unique piece in the form of a waltz. You can read the score, and you can hear a computer generated realization of the music. This is actually a method for quasi-randomly choosing appropriate measures of music from amongst a large database of possibilities composed by a human. Thus, the algorithm is for making selections from among human-composed excerpts—composing a formal structure using human-composed content—not for actually generating notes.
In the 1950s two professors at the University of Illinois, Lejaren Hiller and Leonard Isaacson, wrote a program that implemented simple rules of tonal counterpoint to compose music. They demonstrated their experiments in a composition called the Illiac Suite, named after the Illiac I computer for which they wrote the program. The information output of the computer program was transcribed by hand into musical notation, to be played by a (human-performed) string quartet.
Another important figure in the study of algorithmic music composition is David Cope, a professor from the University of California, Santa Cruz. An instrumental composer in the 1970s, he turned his attention to writing computer programs for algorithmic composition in the 1980s. He has focused mostly on programs that compose music “in the style of” famous classical composers. His methods bear some resemblance to the musical dice game of Mozart, insofar as he uses databases of musical information from the actual compositions of famous composers, and his algorithm recombines fragmented ideas from thos compositions. As did Hiller and Isaacson for the Illiac Suite, he transcribes the the output of the program into standard musical notations so that it can be played by human performers. Eventually he applied his software to his own previously composed music to generate more music “in the style of” Cope, and thus produced many more original compositions of his own. He has published several books about his work, which he collectively calls Experiments in Musical Intelligence (which is also the title of his first book on the subject). You can hear the results of his EMI program on his page of musical examples.
MuLab instructions
The complete documentation for MuLab is available as a set of HTML pages.
Much of the information provided here is extracted from that manual.
Audio Setup
When you first open the application, you may need to set up the communication between the application and the audio driver for your computer’s sound card (audio interface hardware). If the Audio Setup window is not opened for you automatically, you can click on the MuLab button and choose Audio Setup from the menu.
On OSX, choose the Core Audio device driver for the built-in audio of your computer (or for another audio interface, if you have one). On Windows, choose an ASIO or MME device driver. On Windows it’s best to use the specific ASIO driver that comes with your sound device. If no such driver exists then you should try the free device-independent driver Asio4All. Please note that Asio4All is not a MuTools product, if you need support on Asio4All please go to the Asio4All website. If Asio4All isn’t working for you, then select Driver Type = MME Audio, Driver Name = Sound Mapper.
Menus
The menus in MuLab don’t appear in your computer’s main menubar. There are menus that pop up when you click on one of the two buttons labeled MULAB and SESSION, for access to global program settings and operations. However, most of MuLab’s functionality is accessed via the contextual menus that pop up when you right-click an object (control-click, on Macintosh). You can never do something wrong by right-clicking somewhere. On the contrary: try right-clicking every possible object on the screen and you may discover extra functionalities.
MuLab links
Link
This page lists links to several sources of information about how to use the free Digital Audio Workstation (DAW) software MuLab.
You should first download the most recent version of the MuLab software. The MuLab Free version has some limitations but is quite adequate for this class.
The documentation for MuLab is available online or as a downloadable .zip file.
Sometimes you can learn just by examining the work that other people have done. For that purpose, MuTools provides several demo sessions, files containing complete compositions, which you can download, play, and examine to find out how the composer achieved particular sounds.
Here is a video tutorial on the features of the oscillator within the MUX synthesizer plugin that is part of MuLab.
Moog demo
Link
Modular synthesizer terminology
In the 1960s Robert Moog developed a voltage-controlled modular synthesizer. It consisted of a collection of individual electronic modules designed to synthesize sound or alter sound, and those modules could be interconnected in any way desired by using patch cords to connect the output of one module to the input of another module. The user could thus establish a “patch”—a configuration of interconnections for the modules—to create a unique sound, and could then play notes with that sound on a pianolike keyboard that put out voltages to control the frequency of the sound.
I’ll describe a few of the module types that were commonly found in such a synthesizer.
An oscillator is a circuit that creates a repetitively changing signal, usually a signal that alternates back and forth in some manner. That repeating oscillation is the electronic equivalent of a vibration of a physical object; when the frequency of the oscillation is in the audible range it can be amplified and heard. The oscillators in the Moog synthesizer were voltage-controlled, meaning that the oscillation frequency could be altered by a signal from another source.
Electronic oscillators often created certain specific types of waveforms, which were so common that they have come to be known as “classic” waveforms. The most fundamental is the sinusoid (a.k.a. sine wave), which is comparable to simple back-and-forth vibration at one particular frequency. A second classic waveform is the sawtooth wave, so named because it ramps repeatedly from one amplitude extreme to the other, and as the waveform repeats it resembles the teeth of a saw. It contains energy at all harmonics (whole number multiples) of the fundamental frequency of repetition, with the amplitude of each harmonic being proportional to the inverse of the harmonic number. (For example, the amplitude of the 2nd harmonic is 1/2 the amplitude of the fundamental 1st harmonic, the amplitude of the 3rd harmonic is 1/3 the amplitude of the fundamental, and so on.) A third classic waveform is the square wave, which alternates suddenly from one extreme to the other at a regular rate. A square wave contains energy only at odd-numbered harmonics of the fundamental, with the amplitude of each harmonic being proportional to the inverse of the harmonic number. (For example, the amplitude of the 3rd harmonic is 1/3 the amplitude of the fundamental, the amplitude of the 5th harmonic is 1/5 the amplitude of the fundamental, and so on.) A fourth waveform, the triangle wave, ramps back and forth from one extreme to the other. It contains energy only at odd-numbered harmonics of the fundamental, with the amplitude of each harmonic being proportional to the square of the inverse of the harmonic number. (For example, the amplitude of the 3rd harmonic is 1/9 the amplitude of the fundamental, the amplitude of the 5th harmonic is 1/25 the amplitude of the fundamental, and so on.)
An amplifier, as the name implies, serves to increase the amplitude of a signal. In a voltage-controlled amplifier, the amount of signal gain it provides to its input signal can itself be controlled by some other signal.
In a modular system, an oscillator might be used not only to provide an audible sound source, but also to provide a control signal to modulate (alter) some other module. For example we might listen to a sine wave oscillator with a frequency of 440 Hz and hear that as the musical pitch A above middle C, and then we might use a second sine wave oscillator at a sub-audio frequency such as 6 Hz as a control signal to modulate the frequency of the first oscillator. The first, audible oscillator is referred to as the carrier signal, and the second, modulating oscillator is called the modulator. The frequency of the carrier is modulated (altered up and down) proportionally to the shape of the modulator waveform. The amount of modulation up and down depends on the amplitude of the modulator. (So, an amplifier might be applied to the modulator to control the depth of the modulation.) This control of the frequency of one oscillator with the output of another oscillator is known as frequency modulation. At sub-audio rates such as 6 Hz, this frequency modulation is comparable to the vibrato that singers and violinists often apply to the pitch of their tone. The depth of the vibrato can be varied by varying the amplitude of the modulator, and the rate of the vibrato can be varied by varying the frequency of the modulator. When, as is often the case, the modulating oscillator is at a sub-audio control rate, it’s referred to as a low-frequency oscillator, commonly abbreviated LFO.
The diagram below shows schematically how a set of synthesizer modules might be configured to produce vibrato. The boxes labeled “cycle~” are sine wave oscillators, the box labeled “*~” is an amplifier, and the box labeled “+~” adds a constant (direct current) offset to a signal. In this example, the sine wave carrier oscillator has a constant signal setting its frequency at 1000 Hz, and that signal is modified up and down at a rate of 6 Hz by a sinusoidal modulator which is amplified to create a frequency fluctuation of + and – 15 Hz. The result is a sine tone centered on 1000 Hz with a vibrato going up and down 6 times per second causing a fluctuation between 985 and 1015 Hz.
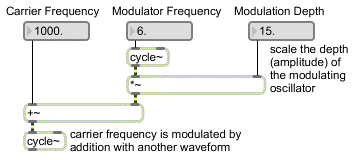
vibrato by means of frequency modulation
A modulating LFO can also be applied to a voltage-controllable amplifier to create periodic fluctuations in the amplitude of a tone. This low frequency amplitude modulation is known in electronic music as tremolo. In electronic music we distinguish between the terms vibrato to describe periodic low-frequency frequency modulation and tremolo to describe periodic low-frequency amplitude modulation. (The Italian word tremolando means “trembling”. In instrumental music the words tremolo and tremolando are used to mean fast repetitions of a note, rather than subtle amplitude fluctuations. However, in electronic music the word tremolo is used to mean periodic change in loudness, similarly to the way vibrato is used to mean periodic changes in pitch. In vocal and instrumental music, vibrato is almost always synchronized with a corresponding fluctuation in loudness—which would be called tremolo in electronic music—thus further complicating the use of the term.)
Very slow frequency modulation can create a sense of the pitch gradually sliding. Sliding pitch is called glissando (an Italian musical term derived from the French word for sliding/gliding, glissant). In the sound example below, a sawtooth modulator LFO at a rate of 0.5 Hz is used to modulate the frequency of a carrier sawtooth oscillator, causing it to glide from 220 Hz to 440 Hz every 2 seconds. The same modulator also controls an voltage-controlled amplifier, which shapes the amplitude of the carrier so that it goes from loud to soft with each two-second glide.
An interesting possibility when using oscillators for modulating the frequency and/or amplitude of another oscillator is that the modulating oscillator might be amplified to produce very extreme fluctuations of pitch or loudness. Perhaps even more importantly, we can also vary the rate of the modulator from sub-audio rates (for classic LFO effects such as vibrato and tremolo) up into audio rates. When this happens, the modulation becomes so fast that we can no longer hear the effect as individual fluctuations, and the frequency modulation and/or amplitude modulation actually produces what are called sidebands—new frequencies that are related to the sum and the difference of the carrier and modulator frequencies, which are not present in the original oscillators themselves but which are generated by the audio-rate interaction of the modulator and the carrier. This can result in various strange and uniquely electronic sounds.
In the sound example below, the frequency of a sawtooth carrier oscillator is modulated by a sine wave LFO passing through an amplifier. At first the frequency of the LFO is sub-audio and its amplification is very low, so the effect is one of very subtle vibrato. Then the amplifier is turned up until the vibrato is extremely wide, making an inhuman warbling. Then the rate of the LFO is turned up until it is well into the audio range, so that we no longer hear it as a frequency fluctuation, but instead we hear many sidebands, creating a complex, inharmonic tone.
A filter is a circuit that can alter the timbre of a sound by reducing or increasing the amplitude of some of the sound’s frequencies. Common filter types are low-pass (pass low frequencies through unchanged, while reducing the amplitude of high frequencies), high-pass (pass high frequencies while reducing the amplitude of low frequencies), band-pass (pass or even emphasize a certain region of frequencies in the spectrum while reducing the amplitude of frequencies below and above that region), and band-reject (a.k.a. notch, to reduce the amplitude of a range of frequencies while passing through the frequencies above and below that region). Such filters can often be varied in terms of the frequencies they affect. Low-pass and high-pass filters are characterized by their cutoff frequency, the frequency at which they begin to substantially alter the frequency spectrum of a sound. For band-pass and band-reject filters, one more commonly refers to the center frequency, the frequency at the center of the affected band. A voltage-controlled filter can have its center frequency or cutoff frequency modulated by another signal source, such as an LFO. This can result in interesting and uniquely-electronic effects of timbre modulation, such as a a periodic filter vibrato or a gliding filter sweep. The sound example below is a 110 Hz sawtooth oscillator being passed through a low-pass filter; the cutoff frequency of the filter is at first being modulated by a sine wave LFO varying the cutoff frequency between 1540 Hz and 1980 Hz, and then the cutoff frequency is slowly swept down to 0 Hz.
We have discussed a few of the most significant types of voltage-controlled modules in the Moog modular synthesizer, such as oscillators, amplifiers, and filters. We’ve discussed four of the classic waveforms produced by the oscillators: sine, sawtooth, square, and triangle. These waveforms can be amplified and listened to directly, or they can be used as control signals to modulate the frequency of another tone. When we modulate the frequency of a tone at a sub-audio rate with a low-frequency oscillator (LFO), the resulting effect is called vibrato; when we modulate the amplitude of a tone (by modulating the gain level of an amplifier) at a sub-audio rate with a low-frequency oscillator (LFO), the resulting effect is called tremolo. Audio-rate modulation of the frequency and/or amplitude of an oscillator results in complex tones with sideband sum and difference frequencies. We’ve also discussed four common filter types: low-pass, high-pass, band-pass, and band-reject. Just as the frequency and the amplitude of a tone can be modulated, the cutoff frequency or center frequency of a filter can likewise be modulated by an LFO to create variations of timbre.
MIDI
By the late 1970s and early 1980s there were quite a few companies manufacturing voltage-controlled electronic synthesizers. Many of those companies were increasingly interested in the potential power of computers and digital communication as a way of providing control voltages for their synthesizers. Computers could be used to program sequences of numbers that could be converted into specific voltages, thus providing a new level of control for the synthesized sound.
In the early 1980s a consortium of synthesizers manufacturers—led by Dave Smith, founder and CEO of the Sequential Circuits company, which made the Prophet synthesizer—developed a communication protocol for electronic instruments that would enable instruments to transmit and receive control information. They called this new protocol the Musical Instrument Digital Interface (MIDI).
The MIDI protocol consists of a hardware specification and a software specification. For the hardware, it was decided to use 5-pin DIN plugs and jacks, with 3-conductor cable to connect devices. The cable establishes a circuit between two devices. Communication through the cable is unidirectional; one device transmits and the other receives. Thus, MIDI-capable devices have jacks labeled MIDI Out (for transmitting) and MIDI In (for receiving), and sometimes also a jack labeled MIDI Thru which transmits a copy of whatever is received in the MIDI In jack. MIDI communication is serial, meaning that the bits of information are transmitted sequentially, one after the other. The transmitting device communicates a digital signal by sending current to mean 0 and no current to mean 1, at a rate of 31,250 bits per second.
For the software specification, it was decided that each word of information would consist of ten bits: a start bit (0), an 8-bit byte, and a stop bit (1). Thus MIDI is theoretically capable of transmitting up to 3,125 bytes per second. A MIDI message consists of one status byte declaring what kind of message it is, followed by zero or more data bytes giving parameter information. In the next paragraphs discussing the actual contents of those bytes, we’ll ignore the start and stop bits, since they’re always the same for every byte and don’t really contain meaningful information.
A status byte always starts with the digit 1 (distinguishing it as a status byte), which means that its decimal value is in the range from 128 to 255. (In binary representation, an 8-bit byte can signify one of 256 different integers, from 0 to 255. The most significant digit is the 128s place in the binary representation.) A data byte always starts with the digit 0 (to distinguish it from a status byte), which means that its decimal value is in the range from 0 to 127.
What do the numbers actually mean? You can get a complete listing of all the messages in the official specification of MIDI messages. Briefly, there are two main categories of messages: system messages and channel messages. System messages contain information that are assumed to be of interest to all connected devices; channel messages have some identifying information coded within them that allows receiving devices to discern between 16 different message “channels”, which can be used to pay attention only to certain messages and not others. (A good metaphor for understanding this would be a television signal broadcast on a particular channel. Devices that are tuned to receive on that channel will pay attention to that broadcast, while other devices that are not tuned to receive on that channel will ignore it.) Let’s take a look at channel messages.
Channel messages are used to convey performance information such as what note is played on a keyboard, whether a pedal is up or down, etc. The types of channel messages include: note-off and note-on (usually triggered by a key on a pianolike keyboard), pitchbend (usually a series of messages produced by moving a wheel, to indicate pitch inflections from the main pitch of a note), continuous control (usually a series of messages produced by a fader, knob, pedal, etc., to describe some kind of curve of change over time such as volume, panning, vibrato depth, etc.), aftertouch (a measurement of the pressure applied to a key after it’s initially pressed), and program messages (telling the receiving device to switch to a different timbre). Rather than try to describe all of these in detail, we’ll look at the format of one particular type of message: note-on.
When a key on a synthesizer keyboard is pressed, two sensors at different heights underneath the key are triggered, one at the beginning and the other at the end of the key’s descent. Since the distance between the two sensors is known, the velocity with which the key was pressed can be calculated by measuring the time between the triggering of the two sensors. (v=d/t) The synthesizer clocks the time between the triggering of the two sensors to detect the velocity of the key’s descent. The synthesizer then sends out a MIDI note-on message telling which key was pressed and with what velocity.
A MIDI note-on message therefore consists of three bytes: message type, key number, and velocity . The first byte is the status byte saying, “I’m a note-on message.” Since the format of a note-on message is specified as having three bytes, the receiving device knows to consider the next two bytes as key number and velocity. The next two bytes are data bytes stating the number of the key that was pressed, and the velocity with which it was pressed. Let’s looks closely at the anatomy of each byte. (We’ll ignore the start and stop bits in this discussion, and will focus only on the 8-bit byte between them.)
A status byte for a note-on message might look like this: 10010000. The first digit is always 1, meaning “I’m a status byte.” The next three digits say what kind of message it is. (For example, 000 means “note-off”, 001 means “note-on”, and so on.) The final four digits tell what channel the message should be considered to be on. A receiving device can use the channel information to decide whether or not it wants to pay attention to the message; it can pay attention to all messages, or it can pay attention only to messages on a specific channel. Although these four digits together can express decimal numbers from 0 to 15, it’s conventional to refer to MIDI channels as being numbered 1 to 16. (That’s just a difference between computer numbering, which almost always starts at 0, and human counting, which usually starts at 1.) So, the four digits 0000 mean “MIDI channel 1”.
The first data byte that follows the status byte might look like this: 00111111. The first digit of a data byte is always 0, so the range of possible values that can be stated by the remaining seven digits is 0 to 127. By convention, for key numbers the decimal number 60 means piano middle C. The number shown in this byte is 63, so it’s indicating that the key D# above middle C is the key that was pressed. (Each integer designates a semitone on the equal-tempered twelve-tone chromatic scale, so counting up from middle C (60) we see that 61=C#, 62=D, 63=D#, and so on.) The next data byte might look like this: 01101101. This byte designates the velocity of the key press on a scale from 0 to 127. The number is calculated by the keyboard device based on the actual velocity with which the key was pressed. The value shown here is 109 in decimal, so that means that on a scale from 0 to 127, the velocity with which the key was pressed was pretty high. Commonly the receiving device will use that number to determine the loudness of the note that it plays (and it might also use that number for timbral effect, because many acoustic instruments change timbre depending on how hard they’re played).
So the whole stream of binary digits (with start and stop bits shown in gray), would be 010010000100011111110011011011. The first byte says, “I’m a note-on message on channel 1, so the next two bytes will be the key number and velocity.” The second byte says, “The key that was pressed is D# above middle C.” The third byte says, “On a scale from 0 to 127, the velocity of the key press is rated 109.” The device that receives this message would begin playing a sound with the pitch D# (fundamental frequency 311.127 Hz), probably fairly loud. Some time later, when the key is released, the keyboard device might send out a stream that looks like this: 010010000100011111110000000001. The first two bytes are the same as before, but the third byte (velocity) is now 0. This says, “The key D# above middle C has now been played with a velocity of 0.” Some keyboards use the MIDI note-off message, and some simply use a note-on message with a velocity of 0, which also means “off” for that note.
Notice that the MIDI note-on message does not contain any timing information regarding the duration of the note. Since MIDI is meant to be used in real time—in live performance, with the receiving device responding immediately—we can’t know the duration of the note until later when the key is released. So, it was decided that a note would require two separate messages, one when it is started and another when it is released. Any knowledge of the duration would have to be calculated by measuring the time elapsed between those two messages.
A complete musical performance might consist of very many such messages, plus other messages indicating pedal presses, movement of a pitchbend wheel, etc. If we use a computer to measure the time each message is received, and store that timing information along with the MIDI messages, we can make a file that contains all the MIDI messages, tagged with the time they occurred. That will allow us to play back those messages later with the exact same timing, recreating the performance. The MIDI specification includes a description of exactly how a MIDI file should be formatted, so that programmers have a common format with which to store and read files of MIDI. This is known as Standard MIDI File (SMF) format, and such files usually have a .mid suffix on their name to indicate that they conform to that format.
It’s important to understand this: MIDI is not audio. The MIDI protocol is intended to communicate performance information and other specifications about how the receiving device should behave, but MIDI does not transmit actual representations of an audio signal. It’s up to the receiving device to generate (synthesize) the audio itself, based on the MIDI information it receives. (When you think about it, the bit rate of MIDI is way too low to transmit decent quality audio. The best it could possibly do is transmit frequencies up to only about 1,500 Hz, with only 7 bits of precision.)
The simplicity and compactness of MIDI messages means that performance information can be transmitted quickly, and that an entire music composition can be described in a very small file, because all the actual sound information will be generated later by the device that receives the MIDI data. Thus, MIDI files are a good way to transmit information about a musical performance or composition, although the quality of the resulting sound depends on the synthesizer or computer program that is used to replicate the performance.
MIDI messages explained
Link
A pretty thorough-yet-readable explanation of MIDI messages can be found in The MIDI Companion by Jeffrey Rona, much of which is available online on Google Books. For understanding common types of channel messages such as note-on, take a look at the chapter titled “Channel Voice Messages“.
A concise technical explanation of MIDI
Link
A short essay by Tom Igoe on MIDI provides some technical information concisely and clearly.
MIDI message specification chart
Link
A complete summary of MIDI messages is provided by the MIDI Manufacturers Association.
Music Technology in the Industrial Age
Technology has always been an important part of the development of music. Musical instruments are perfect examples of technology developed to extend human capabilities. Presumably vocal music and percussion music must have existed before instruments were developed. How else could the idea of making instruments of music occur? Instruments were developed to extend music beyond what we were capable of producing just with our own voice or the sounds of everyday objects being struck.
The development of keyboard instruments (virginal, clavichord, harpsichord, fortepiano, piano) provides a good case study in how instrumental art and craft were driven by musical imperatives, and how music itself was affected by instrument development.
In the industrial revolution, the most transformative technology for music was the phonograph invented by Thomas Edison in 1877 and quickly improved upon by Alexander Graham Bell who developed the idea of engraving the sound signal horizontally on wax cylinders instead of vertically as on Edison’s tinfoil sheets. Bell’s device, patented in 1886, was dubbed the graphophone. At the same time, Emile Berliner was developing a method of engraving the signal horizontally on wax discs, patenting a device called the gramophone in 1887.
Another technology for music reproduction being developed at the same time was the player piano. Many inventors were experimenting with various technologies for a self-playing piano. The idea that eventually proved most viable was a pneumatic system inside the piano in which air from a foot-powered bellows passed through holes in a moving scroll of paper, activating valves for each key of the piano that moved a push rod to push the piano action, playing a note. The player piano became a viable commercial product in the first decade of the twentieth century, and reached the height of its popularity as an entertainment device in the next two decades, but radically diminished in popularity after the economic crash of 1929. Its fading popularity may also be attributed to the rise of radio sales in the 1920s.
The player piano figured in the work of at least two American experimental composers in the twentieth century who composed specifically for that instrument. In 1924 George Antheil composed an extraordinary work titled Ballet mécanique, to accompany an experimental film of the same name by the French artist Fernand Léger, which called for an ensemble of instruments that included four player piano parts, two human-performed piano parts, a siren, seven electric bells, and three airplane propellers. In the 1950s and ’60s Conlon Nancarrow composed over forty works, which he titled Studies, for player piano. Rather than record the music by playing on a roll-punching piano, he punched the paper rolls by hand, which enabled him to realize music of extraordinary complexity, with multiple simultaneous tempos and sometimes superhuman speed.
Thaddeus Cahill patented the Telharmonium, one of the first electronic instruments, in 1896. It was remarkable for its size and complexity, and for its ability to transmit its sound over telephone wires. It gained considerable attention and support from venture capitalists interested in marketing music on demand via the telephone. The idea eventually proved unsuccessful commercially for various reasons, not the least of which was the problem of crosstalk interference from and with phone conversations. The instrument was so large and unwieldy, and consumed so much energy, that it was abandoned and eventually disassembled.
An instrument of much more enduring interest was the theremin, invented by Russian physicist Leon Theremin in 1920, and patented in the U.S. in 1928. It was remarkable because it operated on the principle of capacitance between the performer and the instrument, so that the sound was produced without touching the instrument. It created a pure and rather eerie pitched tone, which could be varied in pitch (over a range of several octaves) and volume based on the distance of the performer’s hands from two antennae. The instrument has retained considerable interest and popularity over the past century, and has been mastered by several virtuosic performers, most famously Clara Rockmore.
Musique Concrète Compositions
Gallery
30-second musique concrète compositions by members of the class AN, JOSHUA BECKER, KEITH CHITTAPHONG, ANDREW CORDON, EDWIN CULHANE, NATALIE DOBRIAN, CHRISTOPHER (professor) EAP, MELISSA GALEAS, JOSUE HO, SAMANTHA IBARROLA, GELLINE JAN, STEPHEN KIM, JI WON KIM, YEUNHI KUO, COLLEEN MOK, CHESLEY … Continue reading
Definition of Technology
Technology means “the application of scientific knowledge for practical purposes” and the “machinery and equipment developed from such scientific knowledge.”
The word is derived the from Greek word tekhnologia, meaning “systematic treatment”, which is composed of the root tekhné, meaning “art, craft” and the suffix -logia, meaning “study (of)”.
In his book Understanding Media: The Extensions of Man (1964), Marshall McLuhan considered technology as a means of extension of human faculties, indeed as an extension of the human body beyond its physical limitations. Of course we use tools—the products of technology—to extend or amplify our physical capabilities. McLuhan pointed out that these extensions provided by technology and media can have both pros and cons.
Music Terminology
“Understanding” or “appreciating” music involves knowing something about the historical and cultural context in which the music was created (who made it? for whom was it made? how was it made? for what purpose was it used? etc.) and also requires having a methodology for analyzing sound, musical structure, and the experience of making and listening to music. Although some people may feel intuitively that everyone should be able to appreciate music naturally, without requiring special training, appreciation of music is actually both a visceral (emotional, gut-level) and an intellectual (rational, brainy) activity. Insofar as music appreciation is intellectual, it’s reasonable to believe that we can improve our appreciation through training and discussion.
One part of understanding music is having a framework of terminology to help us categorize and discuss musical phenomena. To that end let’s take a look at some terms that are used in the discussion and analysis of music, both instrumental and electronic. We can consider the meaning of these terms and can point to examples where the terms may apply.
Rhythm
Each sound is an event that marks a moment in time. We are capable of mentally measuring the amount of time between two events, such as between the onset of two sounds, thus we can mentally compare the time intervals between multiple events. This measurement and comparison process is usually subconscious, but we can choose to pay attention to it, and we can even heighten our capability with a little effort.
If sounds occur with approximately equal time intervals, we notice that as a type of repetition. (We notice that the same time interval occurred repeatedly.) That repetition is a type of pattern that gives us a sense of regularity, like the regularity of our heart beat and our pulse. When sounds exhibit a fairly constant beat or pulse (at a rate that’s not too fast for us to keep up with and not too slow for us to measure accurately in our mind), we are able to think of that as a unit of time, and we can compare future time durations to that unit. When something recurs at a fairly regular rate, we may say that it is periodic, and we refer to the period of time between repeating events. (The period is the reciprocal of the frequency of occurrence.) We’re able to use this period to predict when the next event in the series of repetitions is likely to occur.
We’re also capable of mentally imagining simple arithmetic divisions and groupings of a time period. For example, we can quite easily mentally divide a time interval in half, or multiply it by two, to calculate a new time interval, and we can notice when a time interval is half or twice the beat period.
With this mental measurement process, which allows us to detect arithmetically related time intervals, we can recognize and memorize patterns of time intervals. When we perceive that there is an organization or pattern in a sequence of events, we call that rhythm. We can find relationships between similar rhythms, and we can notice that rhythms are similar even when they are presented to us at a different speed. (A change of speed is also an arithmetic variation, in the sense that all the time intervals are multiplied by some constant value other than 1.) Musicians often refer to the beat speed as the tempo (the Italian word for time).
Pitch
We are able to discern different frequencies of sound pressure vibrations, and can compare those frequencies in various ways. When a sound contains energy at multiple frequencies, as is usually the case, if the frequencies are predominantly harmonically related (are whole number multiples of the same fundamental frequency) we perceive the sound as a unified timbre based on the fundamental frequency. We say that such sounds have a pitch, which refers to our subjective judgement of the sound’s fundamental frequency.
Most people are able to compare pitches, to determine which is “higher” or “lower”; that evaluation is directly related to whether a sound’s fundamental frequency is greater or lesser than that of another sound. With some practice, one can develop a fairly refined sense of relative pitch, which is the ability to identify the exact pitch difference between two pitched sounds; that evaluation is related to the ratio of the sounds’ fundamental frequencies. Thus, whereas we are mentally evaluating the ratio of two fundamental frequencies, we tend to think about it as a difference between two pitches. A geometric (multiplicative) series of frequencies is perceived as an arithmetic (additive) series of pitches.
Even when the sound is inharmonic, we’re sensitive to which frequency region(s) contain the strongest energy. So, with sounds of indefinite pitch, or even with sounds that are fairly noisy (contain many unrelated frequencies), we can still compare them as having a higher or lower pitch, in which case we’re really referring to the general pitch region in which they have the most sound energy. For example a small cymbal that produces mostly high frequency noise will sound higher in pitch than a larger cymbal that has more energy at lower frequencies.
So, even when we’re hearing unpitched sounds, we still can make pitch-based comparisons. A traditional musical melody is a sequence of pitched sounds, but a percussionist can construct a similar sort of melody made up of unpitched sounds, using instruments that produce noises in different pitch regions. Likewise, a musique concrète composer might use non-instrumental sounds of different pitch height to compose a “melody” of concrete sounds.
Motive
In various design fields, the term motif is used to designate the repeated use of a particular distinctive pattern, shape, or color to establish a predominant visual theme. In music composition the term motive (or motif) is used to describe a short phrase that has a distinctive pitch contour and a distinctive rhythm, which is then used repeatedly (with some variation) to create a sense of thematic unity over time. The distinctive aspects of the pitch contour and the rhythm make it easily recognizable to the listener, even when it has been modified in certain ways (such as using the original rhythm with a different pitch contour or vice versa). As the motive reappears in the music, the aspects that remain the same provide a sense of predictability and familiarity for the listener, and the motive’s distinctive traits provide a basis for variation that makes it useful for generating new-but-related ideas.
Counterpoint
Dynamics
Form
Gesture
Dialogue
Technological terms of editing and mixing recorded sound also become compositional ideas and techniques in music that is meant for recording (that is, music that was conceived to exist only as a recording, as opposed to the recording being simply a document of a live performance of the music).
Editing
Looping
Reversal
Fragmentation
Mixing
Panning
Echo
Free Sound
Link
FreeSound.Org is a good website for downloading copyright-free sounds that are often suitable for use in your own musique concrète project.
The Arts Media Center has some sound effects CDs in its collection, too.
Online introduction to computer music
Link
The online Introduction to Computer Music: Volume One by Jeffrey Hass is a pretty clear and concise text. As supplemental reading for the first week of this class, you might want to look at “Chapter 1: An Acoustics Primer” (which I’ve already recommended in an earlier post) and “Chapter 5: Digital Audio“.
Binary number representation
Link
Computers calculate all numbers using binary representation, which means using only two digits: 0 and 1. If you’re not experienced with binary numbers, you might want to take a look at an online lesson on Representation of Numbers by Erik Cheever. Read at least the first two sections — “Introduction” and “Binary representation of positive integers”. (Keep reading beyond that if your brain can handle it.)
For the discussion of quantization of digital audio in this class, a key sentence in that lesson is “With n digits, 2n unique numbers (from 0 to 2n-1) can be represented. If n=8, 256 (=28) numbers can be represented 0-255.” How many different numbers can be represented by 16 digits? (The answer is provided right there on that page.)
The Decibel
Link
If you want to read more about decibels, here’s a pretty good article explaining The Decibel as it’s used to discuss sounds in the real world. (The same principles apply when talking about digital audio, except that the 0 dB reference amplitude in digital audio is usually the greatest amplitude the system can produce, rather than the softest sound we can hear.)